

PostgreSQL에서는 데이터의 트리구조를 표현하기 위해서는 RECURSIVE 키워드를 사용하여 재귀적인 쿼리를 사용할 수있다고 한다.
일단 RECURSIVE 의 사전적인 의미를 알아보면 재귀라는 의미이다.
재귀란 어떠한 것을 정의할 떄 자기 자신을 참조한다는 뜻이다.
즉 자기자신을 참조하여 데이터 트리구조를 표현한다고 보면 된다.
샘플 데이터를 통해 예제를 알아보겠다.
예제 블로그 : http://happy1week.blogspot.com/2012/07/postgresql_19.html
SQL> CREATE TABLE BOM( ITEM_ID INTEGER NOT NULL,
PARENT_ID INTEGER,
ITEM_NAME CHARACTER VARYING(20) NOT NULL,
ITEM_QTY INTEGER,
CONSTRAINT BOM_KEY PRIMARY KEY (ITEM_ID));
SQL> INSERT INTO BOM VALUES (1001, null, ‘컴퓨터’, 1);
INSERT INTO BOM VALUES (1002, 1001, ‘본체’, 1);
INSERT INTO BOM VALUES (1003, 1001, ‘모니터’, 1);
INSERT INTO BOM VALUES (1004, 1001, ‘프린터’, 1);
INSERT INTO BOM VALUES (1005, 1002, ‘메인보드’, 1);
INSERT INTO BOM VALUES (1006, 1002, ‘렌카드’, 1);
INSERT INTO BOM VALUES (1007, 1002, ‘파워’, 1);
INSERT INTO BOM VALUES (1008, 1005, ‘RAM’, 1);
INSERT INTO BOM VALUES (1009, 1005, ‘CPU’, 1);
INSERT INTO BOM VALUES (1010, 1005, ‘그래픽카드’, 1);
INSERT INTO BOM VALUES (1011, 1005, ‘기타장치’, 1);
아래와 같이 데이터를 셋팅후 조회를 하면
데이터를 보면 parent_id가 부모를 나타내고 있다.
[계층형 쿼리 문]
WITH RECURSIVE search_bom(ITEM_ID, PARENT_ID, ITEM_NAME, ITEM_QTY,
LEVEL, PATH, CYCLE) AS (
SELECT g.ITEM_ID, g.PARENT_ID, g.ITEM_NAME, g.ITEM_QTY, 0, ARRAY
[g.ITEM_ID], false
FROM BOM g
WHERE g.PARENT_ID IS NULL
UNION ALL
SELECT g.ITEM_ID, g.PARENT_ID, g.ITEM_NAME, g.ITEM_QTY, LEVEL + 1,
PATH || g.ITEM_ID, g.ITEM_ID = ANY(PATH)
FROM BOM g, search_bom sb
WHERE g.PARENT_ID = sb.ITEM_ID AND NOT CYCLE)
SELECT ITEM_ID, PARENT_ID, lpad('', LEVEL) || ITEM_NAME, ITEM_QTY, LEVEL,
PATH
FROM search_bom ORDER BY PATH
[결과]
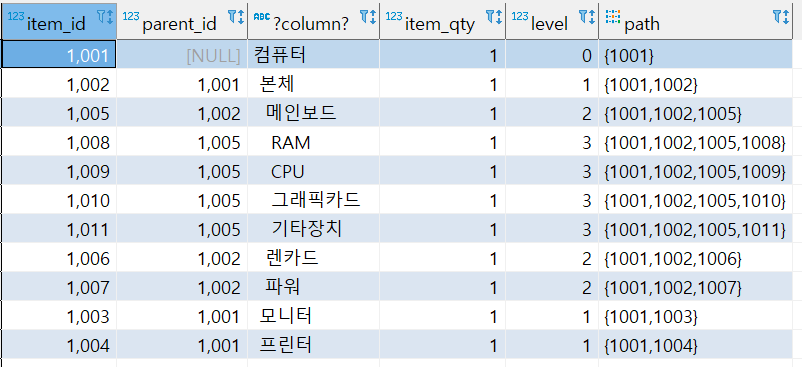
[설명]
쿼리에 대한 설명을 하자면
첫번째 as에 있는 select문은 Root부분이다.
UNION ALL다음의 select문은 재귀가 실행되는 부분이다. 여기서 where 조건은 찾은 레코드의 부모 id와 아이템id가 같다는 조건을 주었다.
AND NOT CYCLE 의 조건은 성능 향상을 위한 조건이다.
재귀가 반복되면서
"이는 RECURSIVE를 통한 재귀쿼리 수행시 성능 상의 문제를 해결하기 위함 이다. WITH 구문 수행 시 CYCLE의 값을 false로 초기화 하였다. 그리고 UNION ALL 다음의 SELECT 구문이 수행되면 CYCLE이 false 이기 때문에 SELECT문이 수행이 되고 검색된 자식 node의 ITEM_ID 값이 배열에 추가된다. 이때 배열에는 부모 ID와 자신의 ID 값이 들어 간다. 그리고 "ANY(PAHT)"에 의해 PAHT 배열에 자신의 ITEM_ID값이 있는지를 검사한다. 검사 결과 이미 찾은 값에 대해 서는 더 이상 데이터 검색을 수행하지 않게 되어 중복 처리를 하지 않게 된다. 물론 이러한 방법을 동원한다 하더라도 오라클의 계층형 쿼리 성능에는 미치지 못하겠지만, 이른 통해 최소한의 성능 향상을 도모할 수 있을 것이다."
'DB > postgresql' 카테고리의 다른 글
| [POSTGRESQL] 시퀀스값 컬럼값 order by로 update하기. (0) | 2023.06.08 |
|---|---|
| [PostgreSQL] 배열 함수(array_agg, array_to_string) (0) | 2022.02.27 |
| [PostgreSQL] EXITS 연산자 (0) | 2022.02.13 |
| postgresql function만들기. (feat. for문) (0) | 2021.02.07 |
